

Why CAPTCHA Exists, Why It Keeps Getting Worse, and Why It May Soon Disappear
Modern bots now look increasingly human. Here's why CAPTCHA keeps becoming more frustrating, how AI is breaking traditional verification systems, and why the future of bot detection may be invisible.
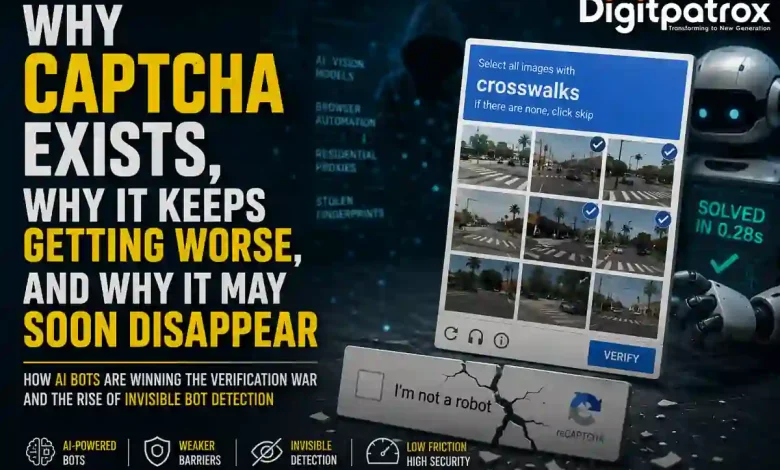
Ten years ago, proving you were human online meant clicking a simple checkbox. Today, you are forced to identify bicycles, traffic lights, crosswalks, buses, and motorcycles across multiple panning image grids-only to be told your submission was ambiguous and you must try again.
The reason for this escalation isn’t that CAPTCHA systems became poorly designed. It’s that bots became dramatically better.
Modern fraud operations no longer rely on primitive request scripts. They deploy fine-tuned visual AI models, distributed residential proxy networks, open-source browser automation frameworks, and stolen device fingerprints. Every improvement on the attacker side directly raises the security bar, creating a worse experience for real people.
Why CAPTCHA Feels Worse Than It Did Five Years Ago
If it feels like navigating the modern web requires an exhausting amount of micro-validation, it isn’t your imagination. The systems tasked with verifying humanity are fundamentally changing because the nature of automation has transformed. Here is exactly why the experience has degraded:
-
AI Vision Defeated Image Puzzles: Automated neural networks can now parse grid-based visual targets with higher speed and accuracy metrics than actual human users.
-
Residential Proxies Weakened IP Reputation: Attackers route automated traffic through compromised IoT devices and legitimate consumer internet connections, making simple IP blacklisting ineffective.
-
Browser Automation Is Harder to Detect: Modern evasion packages allow headless browsers to mirror authentic software lifecycles, simulate human mouse paths, and randomize keystroke delays.
-
Security Vendors Shifted Toward Risk Scoring: Because static barriers fail, defense platforms now use background profiling. If you use privacy-centric settings, you trigger telemetry anomalies that dump you into the hardest puzzle fallbacks.
-
Bots Became Better at Mimicking Messiness: Generative AI tools allow automated agents to simulate human hesitation, packet drops, and non-linear navigation habits, confusing legacy filters.
The CAPTCHA Tax
To understand why browsing the web feels like an ongoing authentication trial, you have to understand a fundamental structural trade-off: The CAPTCHA Tax.
The CAPTCHA Tax: The usability, friction, and processing penalty paid by legitimate users because bot operators keep getting better at mimicking human behavior.
When automated tools are primitive, the tax is near zero. A simple background check on a request header is enough to wave a human through without an explicit challenge. But as malicious automation evolves, the threshold for “trusted behavior” climbs.
[Attacker Sophistication Rises]
│
▼
[Detection Certainty Drops]
│
▼
[The CAPTCHA Tax Increases] ──► (More Puzzles, Higher Friction for Humans)
The biggest threat to CAPTCHA isn’t AI; it’s that browser automation now behaves more consistently than many human users. A script moves deliberately, executes functions linearly, and possesses pristine system variables. Humans hesitate, change their minds, drop packets on unstable mobile connections, and have messy, non-linear navigation habits.
When bot operators use generative AI to simulate that human messiness, the CAPTCHA tax spikes for everyone else. Every time an engineer configures an open-source automation workflow or balances AI agents versus traditional automation, security layers must adapt to separate those legitimate programmatic actions from malicious actors. You are not clicking fire hydrants to prove your humanity; you are paying a structural tax to offset the commoditization of cheap AI execution.
Executive Reality Check
-
The Machine Majority: Automated bot traffic now accounts for 53% of all web traffic, officially outpacing human activity online, according to the Imperva Bad Bot Report. Of that volume, 40% consists of malicious actors performing credential stuffing, inventory hoarding, and scraping.
-
The Core Paradox: CAPTCHA has become progressively more annoying because modern bots increasingly look like real humans. The identical execution footprints force detection algorithms to tighten their filters, catching legitimate users in the crossfire.
-
The AI Baseline: Traditional visual puzzles are increasingly ineffective against modern automated attacks. A landmark study from researchers at ETH Zürich demonstrated that optimized computer vision models (like YOLOv8) can solve Google reCAPTCHA v2 image challenges with 100% accuracy. Commercial solver APIs bypass these barriers for less than $1.00 per thousand successful solves.
-
The Security Illusion: Widespread CAPTCHA visibility is evidence that your bot defense stack is weak. The best bot defenses stop malicious traffic before a challenge is ever shown. If every visitor sees a puzzle, your detection system has already failed to distinguish humans from machines earlier in the request lifecycle.
-
The Infrastructure Shift: Enterprise security teams are deprecating visible grids entirely. Validation is moving down to Web Application Firewall (WAF) edge nodes using passive risk scoring, behavioral entropy, and cryptographic hardware tokens, often achieving validation in under 100ms before a page ever finishes rendering.
The Evolutionary Shift in Bot Defenses
The systems used to verify web traffic have undergone a dramatic structural evolution over the past two decades. Understanding this shift explains exactly why old verification methods failed and why modern infrastructure requires background profiling.
2000s: Text CAPTCHA (Distorted strings / Defeated by baseline OCR)
│
▼
2010s: Image CAPTCHA (Object grids / Defeated by Multimodal Vision AI)
│
▼
2020s: Behavioral Analysis (Mouse entropy, scroll speeds, keystroke timing)
│
▼
Today: Risk Scoring + Fingerprinting + Reputation Systems (JA4, WebGL)
│
▼
Future: Invisible Verification (Hardware attestation, cryptographic signatures)
1. Optical Character Recognition (OCR) vs. Text Strings
Text CAPTCHAs provide limited protection against modern automated attack frameworks. Old, distorted alphanumeric text strings died because baseline neural networks can read twisted text faster and more accurately than a human with excellent vision. Leaving text CAPTCHAs on an endpoint provides virtually zero protection against modern web exploits.
2. Vision Models vs. Image Grids
When CAPTCHAs shifted to “click the traffic lights,” they functioned as a data-labeling engine for early computer vision models. The same advances in computer vision that made image CAPTCHAs possible also made them easier to solve. Multimodal LLMs can process an image grid, isolate the requested semantic objects, and return the exact click coordinates in sub-500ms timeframes, making a mockery of standard visual barriers.
3. Residential Proxy Networks vs. IP Reputation
Historically, you could block automated attacks by blacklisting datacenter IP ranges. Attackers adapted by routing their scraping scripts through residential proxy networks. By hijacking consumer IoT devices or paying for distributed proxy pools, a single automated campaign can launch millions of credential stuffing attempts where every single request originates from a distinct, residential internet connection.
4. Headless Browser Sophistication
Out-of-the-box automation frameworks like Puppeteer or Playwright used to leave explicit footprints in the browser window environment. Modern evasion packages patch these JavaScript variables natively. They simulate human mouse paths, randomize keystroke delays, and mimic authentic browser lifecycles, forcing security platforms to look deeper into the hardware execution stack to catch anomalies.
Why CAPTCHA Flags Real Humans
One of the most frequent points of user frustration is getting trapped in a repetitive, un-solvable puzzle loop despite being an actual human being. This doesn’t happen because you clicked the wrong corner of a traffic light; it happens because your environmental telemetry looks identical to a headless scraping node.
The Tracking Penalty
Modern verification tools look for deep identity markers. Cloudflare Turnstile, Google reCAPTCHA v3, Arkose Labs, hCaptcha, DataDome, HUMAN Security, and Akamai Bot Manager all execute background environmental scrapes.
If you systematically clear your browser state, block third-party trackers, or use privacy-focused configurations, you induce tracking decay. Because the security script cannot access your historical cookie state or calculate a definitive risk score, it drops you directly into its highest-friction fallback route.
The Shared Network Curse
If you browse through a commercial VPN or use iCloud Private Relay, your outbound traffic is routed through a concentrated pool of exit nodes. To an edge Web Application Firewall (WAF), your IP address looks exactly like a high-volume residential proxy pool that was hammering an identity route five minutes ago. You are penalized for the ambient noise of the network you share.
Telemetry Signals Used Behind the Checkbox
-
JA4 TLS Fingerprinting: The edge node inspects the specific configuration parameters, extensions, and cipher suites passed during the initial TLS/SSL handshake. If a request claims to be a standard desktop browser but its TLS structure matches an unpatched code library wrapper, it is flagged as a machine configuration before a single byte of HTML is returned.
-
Canvas & WebGL Rendering Entropy: The security script instructs the browser to silently draw a complex geometric shape using the client’s graphic rendering pipeline. Because variations in graphics cards, system drivers, and OS patch levels create unique pixel-hash outputs, the system can instantly determine if the browser is running inside an authentic hardware environment or an emulated headless container.
What Actually Breaks First (The Operator’s Scars)
Nobody notices CAPTCHA during internal security reviews. They notice it when paid acquisition costs suddenly rise, support queues spike, and conversion rates quietly drop 4% to 9%.
A login page receiving 50,000 requests per day behaves very differently from one receiving 50 million. At smaller volumes, a security team can tolerate high friction to keep the database clean. At enterprise scale, false positives become vastly more expensive than the actual fraud losses they prevent.
A Typical Launch Failure Pattern
Consider a common failure pattern that appears during high-profile product launches. Marketing drives a massive surge of legitimate traffic through paid campaigns. Because the sudden spike triggers anomaly detection rules, the edge bot defenses tighten their thresholds automatically.
Thousands of real users suddenly find themselves forced to complete exhausting visual challenges right before checkout. The security dashboards show a beautifully clean, attack-free deployment, while the e-commerce team watches their conversion rates tank in real time.
Conversion and Retention Destruction
Enforcing a mandatory manual challenge loop on an e-commerce checkout path or a SaaS registration form acts as an immediate funnel tax. Introducing a visual validation step introduces severe abandonment risks among motivated, purchasing users. If your customer acquisition costs are tightly optimized, that security-induced abandonment rate can wipe out your margin.
Broken Automation Pipelines
The moment an enterprise deploys blanket WAF-level challenge rules across an entire domain root, external API and webhook configurations begin to fail. Automated B2B data exchanges, server-to-server requests, and background systems do not have eyes to solve puzzles. They throw raw 403 errors, breaking critical business automation workflows while leaving customer engineering queues flooded with unhelpful system errors.
As teams build modern autonomous workflows or deploy custom internal systems, these automated processes must interact with external interfaces. Standard security gates treat external programmatic actions and automated form submissions as brute-force attacks. Without explicit implementation configurations-like OAuth mechanisms that AI agents depend on-your platform will end up blocking legitimate, automated workflows initiated by your enterprise clients or internal tools, leading to massive engineering overhead as detailed in the hidden costs of scaling AI automation workflows.
Why Many Companies Are Replacing reCAPTCHA
Google’s reCAPTCHA has dominated the verification market for over a decade, but enterprise teams are migrating away from it at an accelerating rate. The push toward alternative platforms like Cloudflare Turnstile is driven by two primary issues: cookie dependence and systemic user friction.
[reCAPTCHA Architecture] ──► Relies on Google Cookies/History ──► High Friction for Private Users
[Turnstile Architecture] ──► Relies on Passive Managed Challenges ──► Low Friction for All Users
Legacy reCAPTCHA implementations determine a user’s risk score heavily based on whether they have a cached, active Google account session in their browser history. If a user is unauthenticated, clears cookies regularly, or browses using a privacy-hardened setup, reCAPTCHA defaults to an aggressive baseline risk score. This forces immediate, high-friction puzzle grids.
Furthermore, enterprise compliance teams face increasing pressure regarding data privacy. Because reCAPTCHA collects client telemetry to optimize its broad risk profiles, organizations in heavily regulated sectors are turning to privacy-first, zero-puzzle alternatives like Cloudflare Turnstile. Turnstile runs independent of identity ecosystems, executing non-intrusive JavaScript challenges at the edge and validating the request in under 100ms without punishing users for blocking third-party tracking cookies.
CAPTCHA Is Becoming a Privacy Trade-Off
The slow migration away from visible puzzles reveals an uncomfortable security truth: The web is becoming less annoying only because it is becoming more heavily monitored.
To achieve a true “zero-friction” web experience where users never click an image grid, security platforms must gather more data from the background browser layer. The future of bot defense relies entirely on deep environment scanning, browser fingerprinting, WebGL hardware analysis, and behavioral entropy.
Visible Friction (Puzzles, Image Grids, Delays)
▲
│ (The Current Structural Trade-Off)
▼
Invisible Surveillance (Hardware Profiling, TLS Fingerprinting, Device Trust)
The emerging alternative to this deep monitoring is cryptographic infrastructure known as Private Access Tokens (PATs). Supported by major platform vendors, PATs leverage hardware-level secure enclaves on your phone or computer to mathematically sign that a device is legitimate and un-tampered with.
While this eliminates both visual puzzles and background data harvesting, it introduces a separate systemic constraint: web access becomes gated by your device hardware tier. Legacy devices or open operating systems that cannot supply verified hardware attestation tokens are forced right back into heavy, high-friction puzzle fallbacks.
Enterprise Strategy: The Shift to Invisible Verification
The consensus among modern engineering architectures is clear: Visible visual puzzles should be treated as a legacy fallback, not a primary defense. Enterprise platforms are shifting to entirely passive edge infrastructure to analyze risk without destroying conversion metrics.
Enterprise Provider Comparison
| Platform | Core Detection Vector | Primary Architectural Strength | Known Implementation Limitation |
| Cloudflare Turnstile | Passive browser telemetry, Private Access Tokens (PATs) | Near-zero user friction, excellent edge network performance, privacy-first data model. | Most effective when embedded natively within a broader Cloudflare WAF ecosystem. |
| Google reCAPTCHA v3 / Enterprise | Historical risk scoring, Google ecosystem tracking | Strong detection based on vast cross-domain identity history. | High friction for users blocking Google cookies; raises long-term data privacy compliance questions. |
| Arkose Labs | Dynamic, adaptive challenges paired with telemetry profiling | Explicitly engineered to break the financial model of automated solver APIs by shifting puzzle formats rapidly. | Requires custom implementation resources and carries premium enterprise licensing overhead. |
| DataDome / HUMAN Security | Real-time server-side and client-side behavioral analysis | Highly specialized protection against advanced credential stuffing and distributed scraping loops. | Can introduce minimal script execution latencies if client-side validation code is unoptimized. |
What Nobody Mentions About Bot Defenses
A pervasive misconception in application security is that serving a high volume of CAPTCHAs means your infrastructure is locked down and safe.
In reality, widespread CAPTCHA visibility is a clear indicator that your bot defense stack is weak.
The best security architectures neutralize malicious automation long before an interactive challenge screen is ever rendered to a client. If your monitoring platforms show that thousands of users are being presented with visual validation grids daily, your edge detection mechanisms are failing to accurately classify standard web traffic.
Furthermore, relying on heavy application-layer challenges to mitigate high-volume distributed denial-of-service (DDoS) attacks can crash your own origin systems. Processing complex cryptographic challenge handshakes inside your core application framework during an active attack vector introduces immense CPU utilization overhead. If you don’t offload that analytical processing to edge proxies or network-level rate limiters, your validation gate becomes the exact bottleneck that completes the outage your attackers were aiming for.
Final Decision Matrix
Use this framework to determine your platform’s verification path based on architectural constraints and transaction risk profiles:
| Operational Metric | Invisible Telemetry (e.g., Turnstile / reCAPTCHA v3) | Edge-Layer WAF Filtering (e.g., DataDome / AWS WAF) | Cryptographic Device Tokens (Private Access Tokens) | Fallback Interactive Puzzles (e.g., Legacy Grids) |
| User Experience Impact | Extremely Low (Passive validation) | Zero (Automated background blocking) | Zero (Hardware-level verification handshake) | High (Manual challenge entry loops) |
| Conversion Risk Factor | Low | Near Zero (For authentic users) | Zero | High (4% – 9% funnel drop-off risk) |
| Primary Protection Profile | Low-to-medium volume automated scripts | Enterprise credential stuffing, volumetric scraping loops | Verified mobile and platform-native sessions | Legacy rate-limiting of primitive scripts |
| Infrastructure Overhead | Low (Drop-in JS + API Verification) | Medium (Requires active WAF management and path rules) | Low (Handled via modern browser ecosystem protocols) | Low |
| Ideal Team Type | Early-stage SaaS, content portals, standard lead forms | High-volume e-commerce, banking portals, core API endpoints | Native mobile applications, modern web infrastructure | High-security internal legacy portals only |
Operational Verification FAQ
Why do I get stuck in endless visual loops where the images never stop loading?
Your browser environment is actively failing behind-the-scenes telemetry validation checks. This happens due to a compromised local proxy IP reputation, mismatched request headers, or blocked canvas rendering pipelines. The system isn’t waiting for you to click the right images; it is deliberately extending the challenge time to naturally slow down what its algorithm classifies as an automated attack thread.
Do bots actually struggle with modern “click the crosswalk” image puzzles?
No. Advanced automated scraping networks use fine-tuned vision models that identify and parse grid-based visual targets with higher speed and accuracy metrics than actual human users. Traditional visual puzzles now function primarily as a crude speed-bump for unoptimized scripts, not an absolute barrier for enterprise-scale targeted data extraction.
Is there a security platform that completely eliminates the need for CAPTCHAs?
You can eliminate manual user challenges for clean traffic paths by deploying advanced edge-level behavioral profiling and cryptographic device attestation. However, you will always require a fallback gate configuration to manage incoming traffic derived from unverified browser contexts, legacy machines, or high-risk residential proxy networks.
Why do some websites work instantly while others serve me multiple puzzles in a row?
Because every site sets a different fraud threshold. A bank protecting wire transfers will tolerate more user friction than a newsletter signup page. The challenge you see is often a business decision based on asset risk, not an unchangeable technical limitation. Platforms must balance this risk carefully when evaluating third-party interfaces, a challenge highlighted in architectural comparisons of chatgpt vs claude vs perplexity.
Do application-layer CAPTCHAs protect systems against enterprise DDoS attacks?
No. CAPTCHAs are application-layer (Layer 7) validation mechanisms. During a massive volumetric distributed denial-of-service attack, forcing your origin servers to generate, track, and validate cryptographic tokens for millions of automated requests will exhaust your compute infrastructure resources, crashing your site. Volumetric protection must be managed at the routing and DNS layer long before an application challenge is ever invoked, an essential architectural requirement when designing resilient defenses for AI cybersecurity in 2026.
The Opaque Road Ahead
CAPTCHA is not disappearing because the security problem has been solved. It is disappearing because the puzzle itself no longer works.
The future of bot defense is not proving that you are human. It is continuously estimating the probability that you are.
That shift removes friction for legitimate users. It also requires websites to collect more signals, perform more analysis, and place more trust in opaque risk-scoring systems. The checkbox is dying. The surveillance layer replacing it is only getting started.